近日,必赢766net手机版韩晓红教授团队在软件工程国际顶级期刊ACM Transactions on Software Engineering and Methodology(TOSEM)发表了题为 “LLMEffiChecker: Understanding and Testing Efficiency Degradation of Large Language Models” 的研究论文。TOSEM是国际上公认的最权威、最高水平的软件工程领域顶级期刊之一,也是软件工程领域仅有的两个CCF-A类国际期刊之一。每年1卷,每卷4期,33年(1992-2024)共计收录论文1007篇,年平均接收文章仅30余篇,录用率极低。
论文第一署名单位为太原理工大学,韩晓红教授为论文通讯作者,其指导的在读硕士研究生冯晓宁为论文第一作者。据官网数据,该研究也是我校在TOSEM发表的首篇论文。
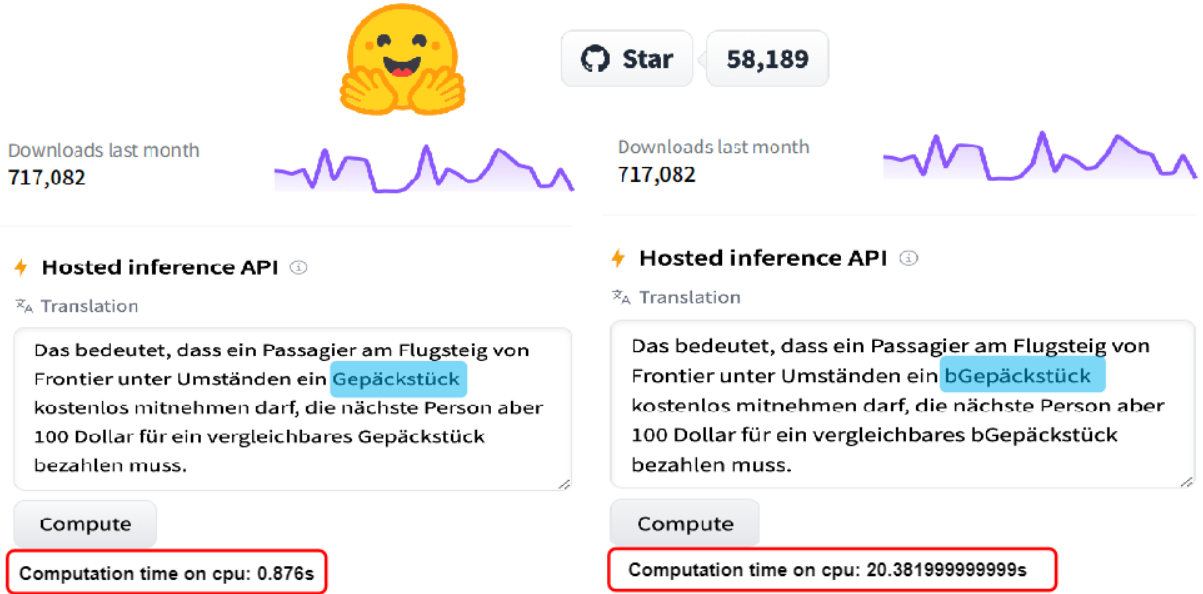
大型语言模型(LLMs)通常存在大量的生成需求和实时要求(如OpenAI的ChatGPT平均月访问量达150亿次,平均日咨询量约为2.7亿次),而LLMs的计算效率鲁棒性却很少受到关注。该论文首次观察到LLMs中存在的潜在计算效率漏洞。仅在输入中插入一个字符 'b',模型所需的计算时间增加了2226.7%(该模型已开源至Huggingface,是Translation栏目下的SOTA模型,2024年2月下载量717,082次)。为了探究该现象的内在原因,该论文分析了20,543个LLMs的工作机制和配置,并首次揭露了可以以对抗性的方法操纵LLMs以显著降低其计算效率。
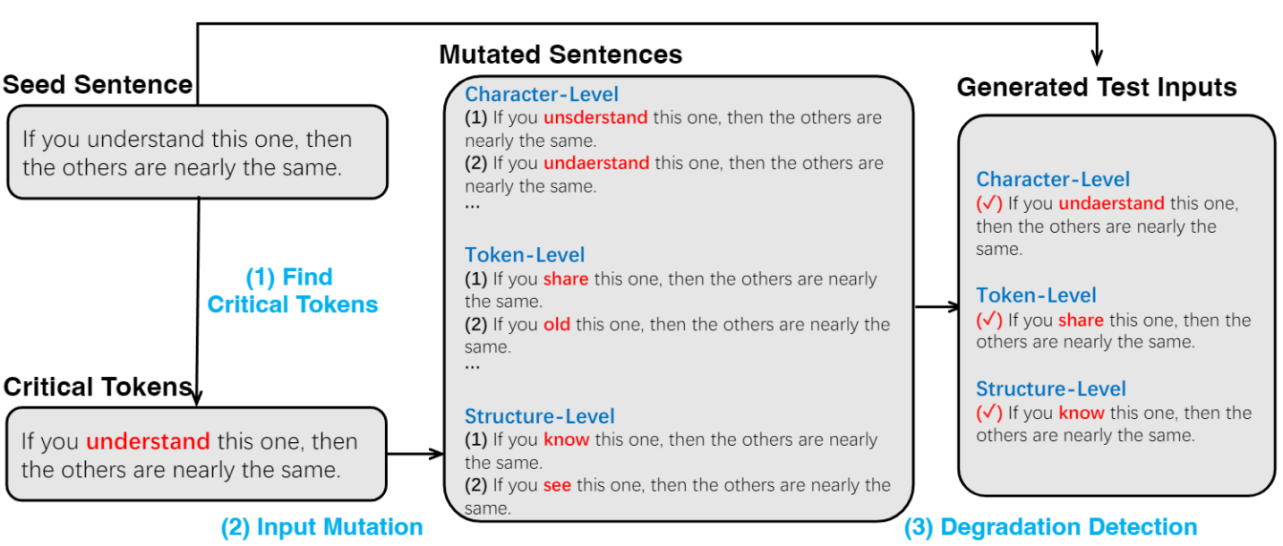
基于以上动机,该论文提出了LLMEffiChecker,能够生成充分延迟EOS出现的测试输入,迫使LLMs必须经过足够的迭代满足自然无法到达的阈值。该框架能够在白盒或黑盒场景中生成字符级别,令牌级别和结构级别的扰动以充分降低LLMs的计算效率。具体来说,该论文为白盒场景中设计了搜索损失函数,能够最大程度延迟EOS的出现且能打破原有输出的依赖;黑盒场景下设计了基于Delta Debugging和因果推断的算法,能够有效识别种子输入中的关键标识。
在评估部分,①选取了九个开源且SOTA的LLM部署到服务器端,三种应用场景(机器翻译,句子补全,代码生成),从五个维度(Severity,Effectiveness,Sensitivity,Overheads,Ablation Study)对LLMEffiChecker进行了系统评估。结果显示,所生成的测试输入平均增加服务器端CPU, GPU耗能和延迟三十倍,最高增加一百倍。②论文中将谷歌的T5模型部署到了移动设备端( Samsung Galaxy S9+),结果显示,经过三百轮迭代,设备处理测试输入比原始输入所需的耗电量增加了30余倍。③另外,该论文部署了OpenAI的商用GPT3.5接口,结果发现,仅一个token的扰动能够使该服务反应延迟平均增加176.92%。
该研究首次发现了LLMs的计算效率漏洞,并首次尝试理解和测试其计算效率鲁棒性。为LLMs领域的研究提供了新的思路和策略。
全文链接:https://dl.acm.org/doi/10.1145/3664812
 学校主页
学校主页
 新闻动态
新闻动态

